

逻辑智能推出LLaSO开源框架!让语音助手听出“弦外之音”
你是否想过,未来的智能音箱或手机语音助手,不仅能准确识别你的每一句话,还能听出你语气中的疲惫、兴奋或是焦虑?在你口述一段会议录音后,它不仅能生成文字稿,还能自动提炼摘要、分析每个人的发言情绪?
这些场景的实现,依赖于一种能深度理解和处理人类语音的大型AI模型。然而,与当前能“看懂”图像的大模型飞速发展不同,语音大模型领域的发展一直显得有些“各自为战”,进展缓慢。
该领域长期被碎片化的技术路线、不透明的训练数据和缺失的统一评测标准所困扰,导致各种模型难以公平比较,严重阻碍了技术的进步。许多研究虽然发布了模型,但其成功的关键——训练数据和方法细节——却常常被“雪藏”起来。
为了打破这一僵局,北京深度逻辑智能科技有限公司推出了LLaSO——首个完全开放、端到端的语音大模型研究框架。它像一个“全家桶”,打包提供了高质量的数据、统一的评测基准和强大的基础模型,旨在为整个行业铺平道路,加速创新。
LLaSO已上线始智AI-wisemodel开源社区,欢迎大家前去体验。

为什么语音大模型的发展会遇到瓶颈?这就像一群顶尖厨师,虽然各有绝活,但因为菜谱、厨具和评价标准完全不同,大家根本不知道谁的厨艺更胜一筹,也难以学习借鉴。该领域主要面临几大核心挑战:
1、技术路线分歧:在如何让AI同时理解语音和文字上,目前的技术路线非常多,但没有一个公认的、效果最好的标准范式。
2、数据私有化:许多领先模型都依赖私有的海量数据进行训练。这使得其他研究者无法复现其结果,也难以判断模型的优越性是来自算法创新还是数据“堆料”。
3、任务范围局限:现有数据集大多只关注“语音转文字”等基础任务,而忽略了语音中更丰富的信息,例如情感、口音、语调和说线、交互模式单一:
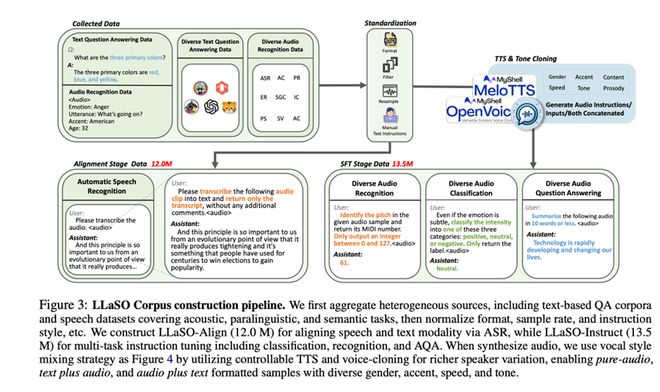
:一个拥有1350万样本的多任务指令库。它不再局限于简单的语音转文字,而是涵盖了20种不同的任务,不仅能识别文字,还能识别说话人的情感、口音、年龄,甚至判断话语的意图。这正是打造下一代智能助理和高效会议纪要工具的关键。更重要的是,它系统性地支持三种交互模式,包括纯语音对话。
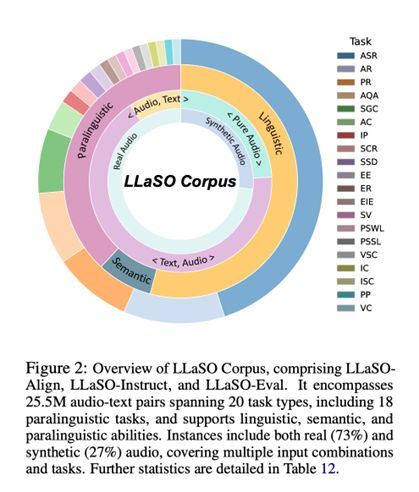
:一个包含超过1.5万个样本的“标准化考场”。所有模型都可以在这个统一的基准上进行测试,得分高低一目了然,确保了评估的公平性和可复现性。
这三大组件共同构成了一个完整的训练、微调和评估流水线,为语音大模型研究提供了前所未有的开放性和便利性。
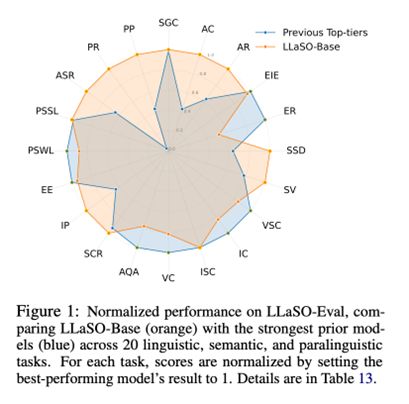
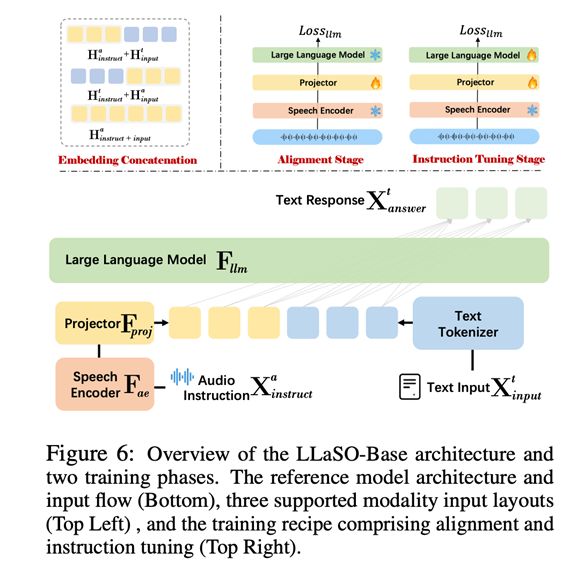
为了验证LLaSO框架的有效性,逻辑智能团队还训练并发布了一个名为LLaSO-Base的参考模型。该模型拥有38亿参数,其设计目标并非追求性能的极致,而是为了提供一个完全依赖LLaSO公开数据、可被轻松复现的强大基线。
LLaSO-Base采用了已被验证的成功架构,由三部分组成:一个语音编码器(听觉)、一个投影器(转换)和一个大型语言模型(大脑)。
数据显示,LLaSO-Base的综合归一化得分达到了0.72分,在所有11个参与评测的主流模型中位列第一,显著优于第二名Kimi-Audio(0.65分)和第三名Qwen2-Audio(0.57分),证明了LLaSO框架的有效性。
:经过更多样化任务训练的模型,不仅综合性能更强,也更“听话”,不容易拒绝回答问题。
开源社区建设需要长期坚持和投入,更需要广大用户的积极参与、贡献和维护,欢迎大家加入wisemodel开源社区的志愿者计划和开源共创计划。期待更多开发者将开源成果,包括模型、数据集和代码等发布到社区,共建中立、开放的AI开源社区生态。欢迎扫码添加wisemodel微信,申请加入wisemodel社群,持续关注wisemodel.cn开源社区动态,
欢迎投稿分享人工智能领域相关的优秀研究成果,鼓励高校实验室、大企业研究团队、个人等,在wisemodel平台上分享各类优质内容,可以是AI领域最新论文解读、最新开源成果介绍,也可以是关于AI技术实践、应用和总结等。投稿可以发邮件到,也可以扫码添加wisemodel微信。
始智AI wisemodel.cn开源社区由清华校友总会AI大数据专委会副秘书长刘道全创立,旨在打造和建设中立开放的AI开源创新社区,将打造成“HuggingFace”之外最活跃的AI开源社区,汇聚主要AI开源模型、数据集和代码等,欢迎高校科研院所、大型互联网公司、创新创业企业、广大个人开发者,以及政府部门、学会协会、联盟、基金会等,还有投资机构、科技媒体等,共同参与建设AI开源创新生态。
